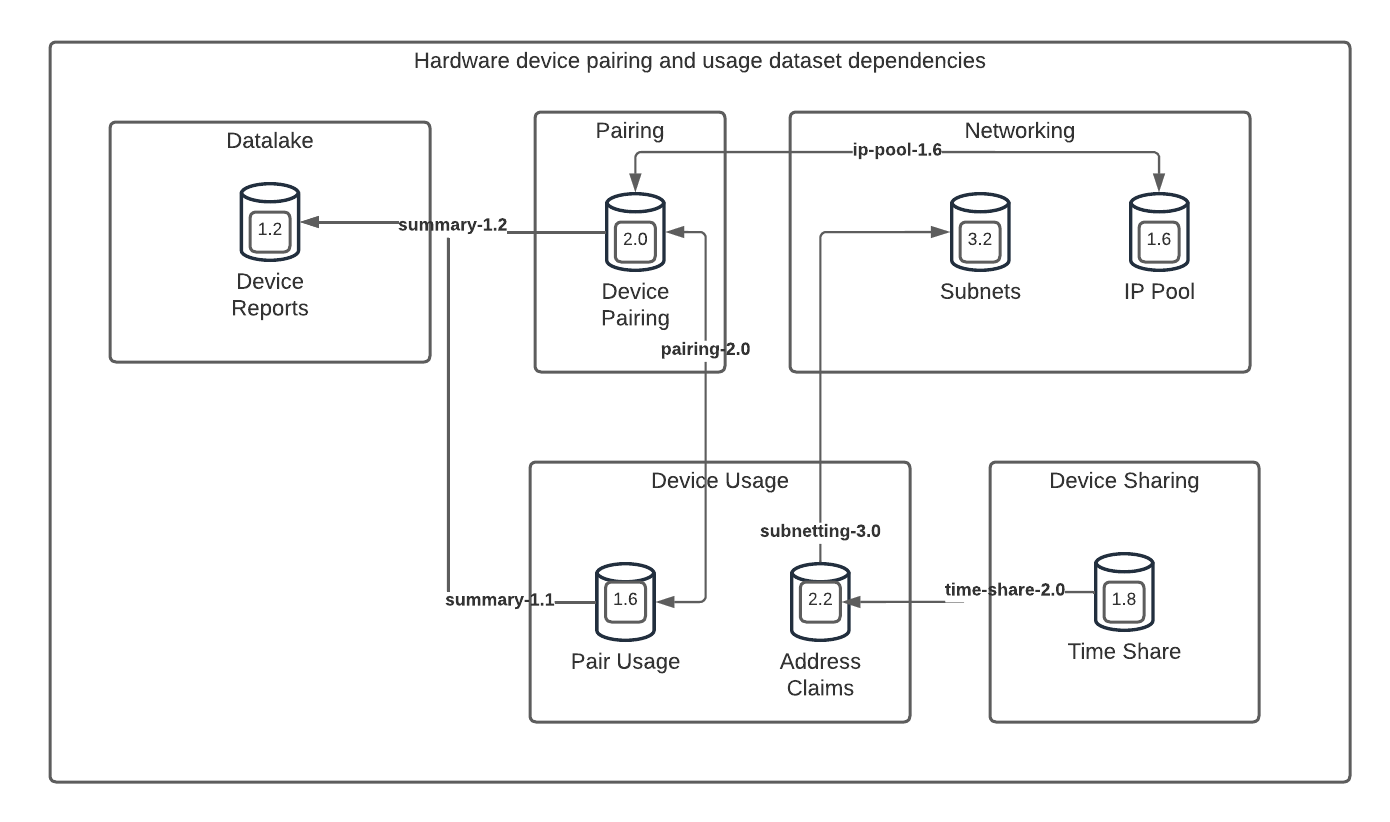
Dependency Management
Datasets have version numbers
A Depot package is a collection of schemas (tables, views, functions, stored procedures) and a dataset is an instance of a package deployed, as part of a service, to a Depot environment.
Each instance of a dataset is therefore associated with a package version. This version number tells consumers exactly which tables, views, and functions are deployed in an environment.
Datasets can depend on other datasets
When a dataset depends on database objects in another database, for example, a SQL query in a view uses a function from another database, that dependency is specified as a Node package dependency. The developer can then write SQL and tests using any object defined as a dependency.
When that package is deployed as a dataset, Depot will find the dependency using a lookup in the environment.
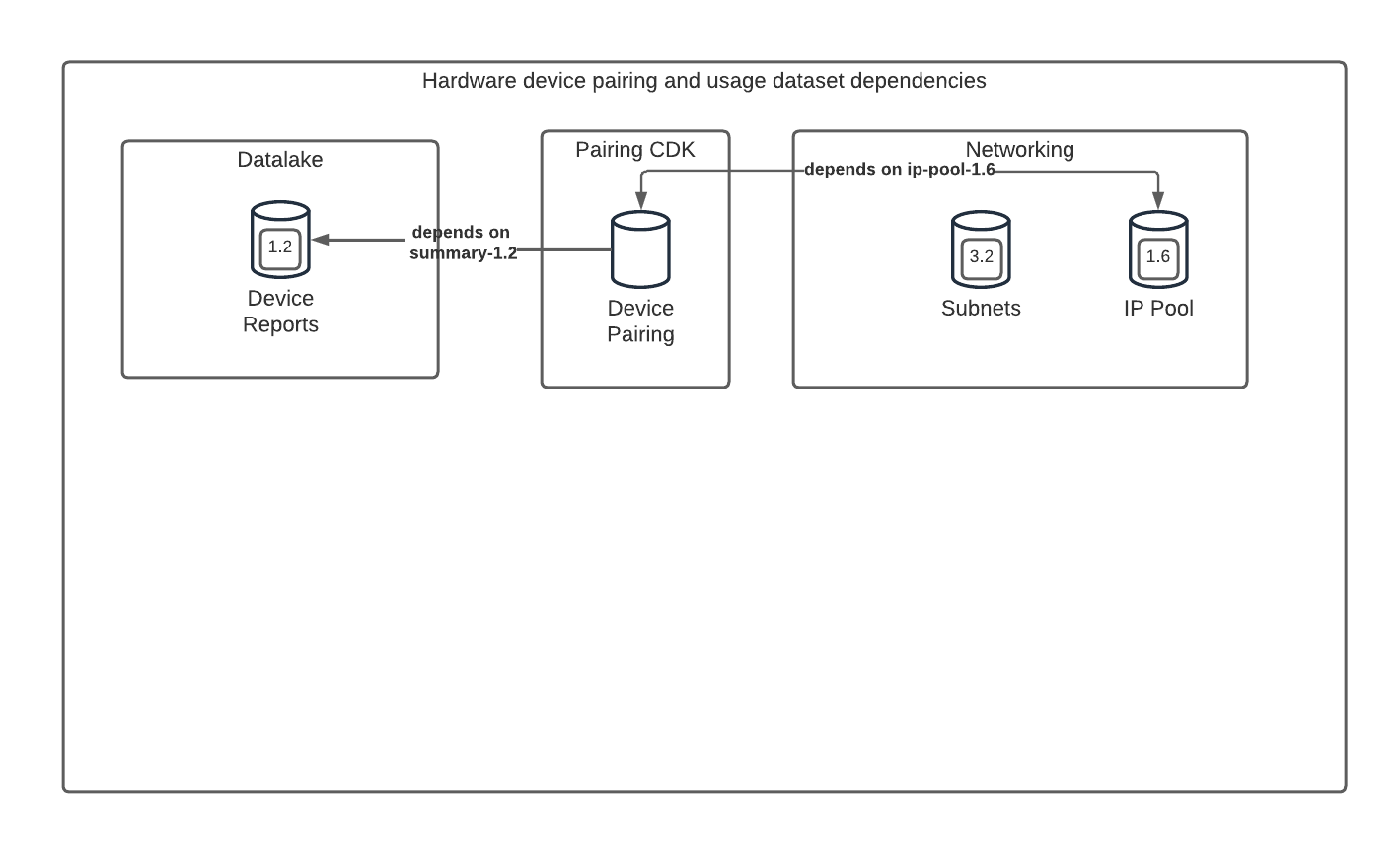
Dependencies are resolved on deployment
Dataset dependencies must form a directed acyclic graph, any cyclic dependencies will be detected and rejected during deployment
Dataset configurations are loaded from the environment's configuration repository and then sorted in topological order based on the combined DAG, before being passed through for deployment for creates/updates.
Once a dataset is successfully deployed, SQL views that depend on objects in other databases, are wired up to the deployed database objects in the environment.
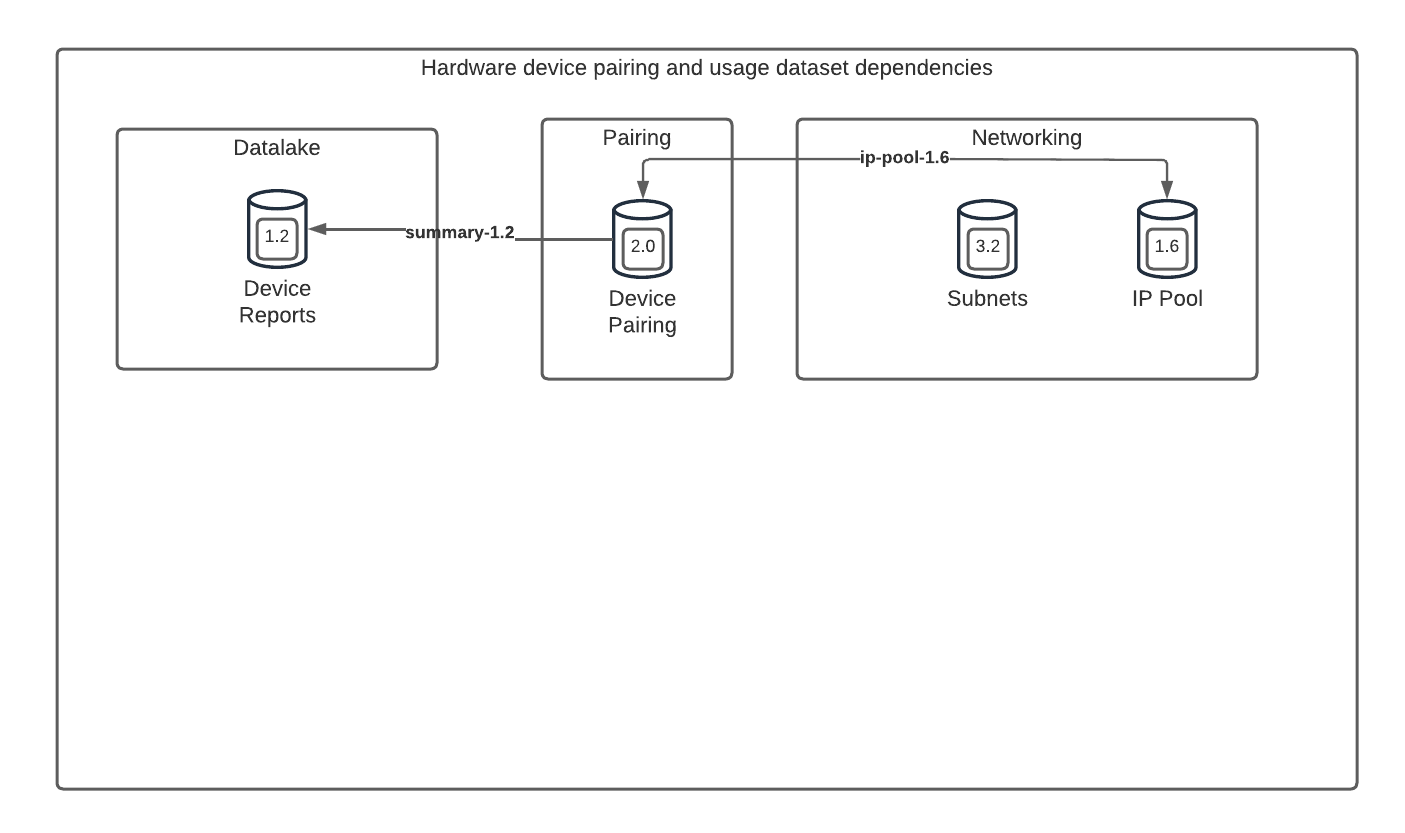
Dataset versions only need to be schema compatible
The expected and actual dataset versions don’t need to match exactly, they only need to be compatible - that is to say that consumers can continue to read data using the older schema, for example after adding a new optional field to a table, a SQL view that is unaware of the new field can still run.